这是人工智能作业的实验报告,其中有对ResNET论文原理的叙述。
一、实验内容
A. 使用ResNet完成图像分类
阅读论文:Deep residual learning for image recognition (压缩包中已提供),使用PyTorch手动搭建一个ResNet网络(可使用任意ResNet变体,如ResNet-18, ResNet-34等),完成一个图像分类任务,根据自己的算力情况,完成MNIST或Cifar-10数据集上的图像分类任务,提交实验报告及代码。
要求:
- 实验报告中包含对论文的理解,为什么ResNet是有效的?
- 实验报告中包含对核心代码的解释(至少包含数据集的预处理、ResNet的定义)。
- 实验报告中需要提供损失值以及准确率的收敛曲线。
- (可选)实验报告中可以探究不同模型参数对结果的影响。
二、实验原理
2.1 论文概述
ResNet,全称是Residual Net,又称作残差神经网络。
通过阅读论文,可以了解ResNet的大致原理。引用论文中的一段阐述。
We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions.
这段论述大意为,我们将层重新表述为学习相对于层输入的残差函数,而不是学习无参考的函数。
ResNet的核心思想是引入**“残差连接”或“跳跃连接”**(skip connection),即让每一个神经网络层学习残差(Residual)。
-
在传统的网络层中,我们希望学到某种映射$$H(x)$$(也即学习到一种难以直观理解的函数)
-
而在ResNet中,我们希望学到残差映射$$F(x)=H(x)−x$$,因此$$H(x)=F(x)+x$$。
这样,网络层实际上学习的是输入和输出之间的残差。通过这种方式,可以使得信息更容易在网络中传播,从而缓解梯度消失问题。
为什么需要残差映射?论文中提到的关键问题是为了是网络退化(这是一个很奇怪但是就是存在的问题)。
When deeper networks are able to start converging, a degradation problem has been exposed: with the network depth increasing, accuracy gets saturated (which might be unsurprising) and then degrades rapidly. Unexpectedly, such degradation is not caused by overfitting, and adding more layers to a suitably deep model leads to higher training error, as reported in and thoroughly verified by our experiments.
对一个朴素网络叠加更多层之后,网络的误差会变大,准确性会下滑。而且令人意外的是,这种退化并不是由过拟合引起的(下面这段论述解释了为什么这个现象不是过拟合引起的)。
Let us consider a shallower architecture and its deeper counterpart that adds more layers onto it. There exists a solution by construction to the deeper model: the added layers are identity mapping, and the other layers are copied from the learned shallower model. The existence of this constructed solution indicates that a deeper model should produce no higher training error than its shallower counterpart. But experiments show that our current solvers on hand are unable to find solutions that are comparably good or better than the constructed solution (or unable to do so in feasible time).
如果直观思考的话,往一个神经网络中添加一大堆恒等映射层(就是什么都不做,输出输入相同),网络的准确性是不会改变的。但是现实就是,添加了这些层之后,就出现了网络退化问题。
这没有一个很好的解释,但是问题就存在在这:因为单纯的层数增加,即使这些层就是恒等映射都会导致网络退化。
因此很自然就想到,一个可行的办法是让一些输入直接跳接到后面的层中。
反映到实际方法上,就是直接在一些层的后面加上原始输入。
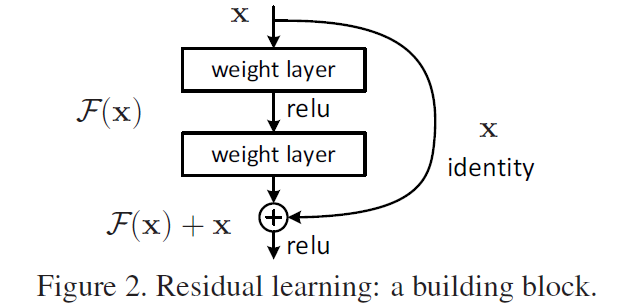
仔细思考,此时中间这两个层经过学习之后,学习到的是什么?
因为我们开始要学习一个映射,但是现在我们往输出加了输入,然后我们整个网络经过训练最后还是会变成,那么神经网络为了能够收敛,学习到的正是。
2.2 网络架构
上述的结构可以封装为一个模块,我们称之为残差模块。
根据上述论文的图示,我们设想一个模块应该有如下的功能:
- 进行卷积运算、批量归一化和ReLU激活。
- 将输入直接通过短路连接添加到卷积运算的结果上。
ResNET相比起CNN来讲,只是多了数个这样的残差块而已。
2.3 流程图
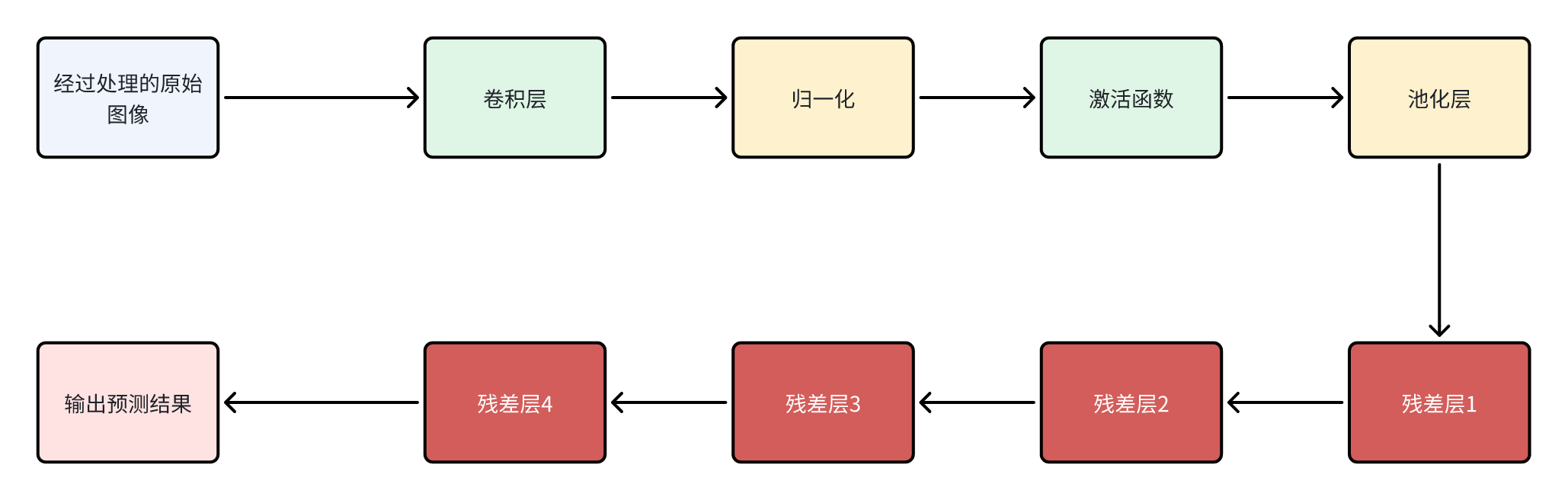
这也是一个很标准的ResNET18的结构。
为什么明明只有6个层,却叫做ResNET18呢?
因为每个残差层里面是自己定义的。我期望一个残差块里的结构应该如下:
- 卷积层1(第一层)
- 归一化
- 激活函数
- 卷积层2(第二层)
- 归一化
然后,每一个残差层里包含两个残差块,即一个残差层里会包含四个层。
这样就一共有个层了。
三、代码展示
悲报:由于我的电脑只有CPU没有显卡加速,在写好ResNET18之后尝试跑,跑了20分钟一轮都没跑完的情况下把电脑跑蓝屏了。无奈之下,我只能改用ResNET8,即将四个残差层删减之一个,程序才能勉强跑起来。
首先,pytorch中没有方便的残差层直接拿过来实现。不过,鉴于残差层本质上是由一个完整的神经层加上最后的短接形成的。因此我们可以自己定义一个类把我们想要的功能整合到一个类中实现。
3.1 残差块
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = F.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample:
residual = self.downsample(x)
out += residual
out = F.relu(out)
return out
这些功能几乎和CNN的功能相同,最后一个out的操作也很容易理解。
这里解释一下,downsample是下采样功能,用来防止后面的层和输出结果对不上。这样就可以免去计算的烦恼。
3.2 ResNet8模块
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=10):
super(ResNet, self).__init__()
self.in_channels = 64
self.conv = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self.make_layer(block, 64, layers[0])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(64, num_classes)
def make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
if stride != 1 or self.in_channels != out_channels:
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels),
)
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels
for _ in range(1, blocks):
layers.append(block(self.in_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
其他的函数我们见得多了,但是出现了一个新的模块make_layer()。我们现在来逐个解释其中的含义。
downsample = None
if stride != 1 or self.in_channels != out_channels:
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels),
)
- 这一步是用来下采样使用的。如果上一层的输出对不上这里的输入的话,我们必须通过中间加一个卷积层和归一化把输出调整成输入能够接受的形式。
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels
for _ in range(1, blocks):
layers.append(block(self.in_channels, out_channels))
layer作为一个列表,存储的是层,即我们把每一个层都当作了一个元素存进了数组中。然后我们根据传递参数决定一层里面有几个残差块。
return nn.Sequential(*layers)
- 这个函数让这个层列表转换成了
pytorch需要的格式。很方便的函数。
3.3 ResNet函数
def ResNET8(num_classes=10):
return ResNet(ResidualBlock, [2], num_classes)
这一步是为了程序更加方便的调用执行。这种写法可以发现,ResidualBlock是可以换成其他函数的。这样的协防让程序充满了可拓展性。
3.4 训练函数
def train(model, train_loader, criterion, optimizer, num_epochs, epoch_losses_list, epoch_accuracy_list):
print("-------START TRAINING-------")
print("num_epochs =", num_epochs)
print("model = ResNET8")
for epoch in range(num_epochs):
print("--------------")
print("epoch", epoch+1)
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / len(train_loader.dataset)
print(f'Finish. Loss: {epoch_loss:.4f}')
epoch_losses_list.append(epoch_loss)
evaluate(model, test_loader, criterion, epoch_accuracy_list)
训练时几乎和CNN的时候一模一样。
不仅如此,接下来的几个函数也几乎都是和CNN相同的,因此不会再作进一步解释。
3.5 检验函数
def evaluate(model, test_loader, criterion, epoch_accuracy_list):
model.eval()
test_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
outputs = model(inputs)
loss = criterion(outputs, labels)
test_loss += loss.item() * inputs.size(0)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
test_loss = test_loss / len(test_loader.dataset)
print(f'Test Loss= {test_loss:.4f}, Accuracy= {accuracy:.2f}%')
epoch_accuracy_list.append(accuracy)
3.6 画图函数
def plot_loss(losses):
"""
绘制损失值随 epoch 变化的图。
参数:
losses (list of float): 每个 epoch 的损失值平均值的列表。
"""
epochs = range(1, len(losses) + 1) # 生成 epoch 的序列 [1, 2, 3, ..., len(losses)]
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure(figsize=(10, 5)) # 设置图形大小
plt.plot(epochs, losses, 'b', label='训练loss曲线') # 绘制损失值曲线,'b'表示蓝色线
plt.title('loss随epoch变化曲线图') # 图像标题
plt.xlabel('Epochs次数') # x轴标签
plt.ylabel('Loss大小') # y轴标签
plt.legend() # 显示图例
plt.grid(True) # 显示网格
plt.show() # 显示图像
def plot_accuracy(accuracy_list):
"""
绘制准确率随 epoch 变化的图。
参数:
accuracy_list (list of float)
"""
epochs = range(1, len(accuracy_list) + 1)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure(figsize=(10, 5)) # 设置图形大小
plt.plot(epochs, accuracy_list, 'b', label='准确率曲线') # 绘制损失值曲线,'b'表示蓝色线
plt.title('准确率随epoch变化曲线图') # 图像标题
plt.xlabel('Epochs次数') # x轴标签
plt.ylabel('准确率') # y轴标签
plt.legend() # 显示图例
plt.grid(True) # 显示网格
plt.show() # 显示图像
3.7 主函数
if __name__=='__main__':
print("----------Program START----------")
epoch_losses_list = []
epoch_accuracy_list = []
model = ResNET8(num_classes=10)
print("ResNET8 ready.")
transform = transforms.Compose(
[transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
print("start to download CIFAR-10...")
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=2)
print("CIFAR-10 ready.")
test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=100, shuffle=False, num_workers=2)
print("loader ready.")
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
num_epochs = 20;
train(model, train_loader, criterion, optimizer, num_epochs, epoch_losses_list, epoch_accuracy_list)
print("--------------")
print("Training Finish.")
# 评估模型
evaluate(model, test_loader, criterion, epoch_accuracy_list)
plot_loss(epoch_losses_list)
plot_accuracy(epoch_accuracy_list)
四、结果展示
最后实验代码跑出来的结果如下。
----------Program START----------
ResNET8 ready.
start to download CIFAR-10...
Files already downloaded and verified
CIFAR-10 ready.
Files already downloaded and verified
loader ready.
-------START TRAINING-------
num_epochs = 20
model = ResNET8
--------------
epoch 1
Finish. Loss: 1.4996
Test Loss= 1.4736, Accuracy= 46.91%
--------------
epoch 2
Finish. Loss: 1.2029
Test Loss= 1.3536, Accuracy= 51.32%
--------------
epoch 3
Finish. Loss: 1.0499
Test Loss= 1.0975, Accuracy= 60.77%
--------------
epoch 4
Finish. Loss: 0.9424
Test Loss= 1.0323, Accuracy= 62.77%
--------------
epoch 5
Finish. Loss: 0.8776
Test Loss= 1.1024, Accuracy= 61.99%
--------------
epoch 6
Finish. Loss: 0.8151
Test Loss= 0.8779, Accuracy= 69.67%
--------------
epoch 7
Finish. Loss: 0.7757
Test Loss= 0.8543, Accuracy= 70.06%
--------------
epoch 8
Finish. Loss: 0.7394
Test Loss= 0.8283, Accuracy= 71.33%
--------------
epoch 9
Finish. Loss: 0.7117
Test Loss= 0.8113, Accuracy= 71.74%
--------------
epoch 10
Finish. Loss: 0.6840
Test Loss= 0.8477, Accuracy= 70.78%
--------------
epoch 11
Finish. Loss: 0.6610
Test Loss= 0.7801, Accuracy= 72.98%
--------------
epoch 12
Finish. Loss: 0.6395
Test Loss= 0.7281, Accuracy= 75.32%
--------------
epoch 13
Finish. Loss: 0.6235
Test Loss= 0.6794, Accuracy= 75.95%
--------------
epoch 14
Finish. Loss: 0.6077
Test Loss= 0.6938, Accuracy= 75.80%
--------------
epoch 15
Finish. Loss: 0.5937
Test Loss= 0.7213, Accuracy= 75.36%
--------------
epoch 16
Finish. Loss: 0.5757
Test Loss= 0.6768, Accuracy= 76.34%
--------------
epoch 17
Finish. Loss: 0.5646
Test Loss= 0.6648, Accuracy= 77.30%
--------------
epoch 18
Finish. Loss: 0.5490
Test Loss= 0.6453, Accuracy= 77.94%
--------------
epoch 19
Finish. Loss: 0.5425
Test Loss= 0.6946, Accuracy= 76.63%
--------------
epoch 20
Finish. Loss: 0.5281
Test Loss= 0.6681, Accuracy= 77.64%
--------------
Training Finish.
Test Loss= 0.6695, Accuracy= 77.27%
绘制出的曲线如下。
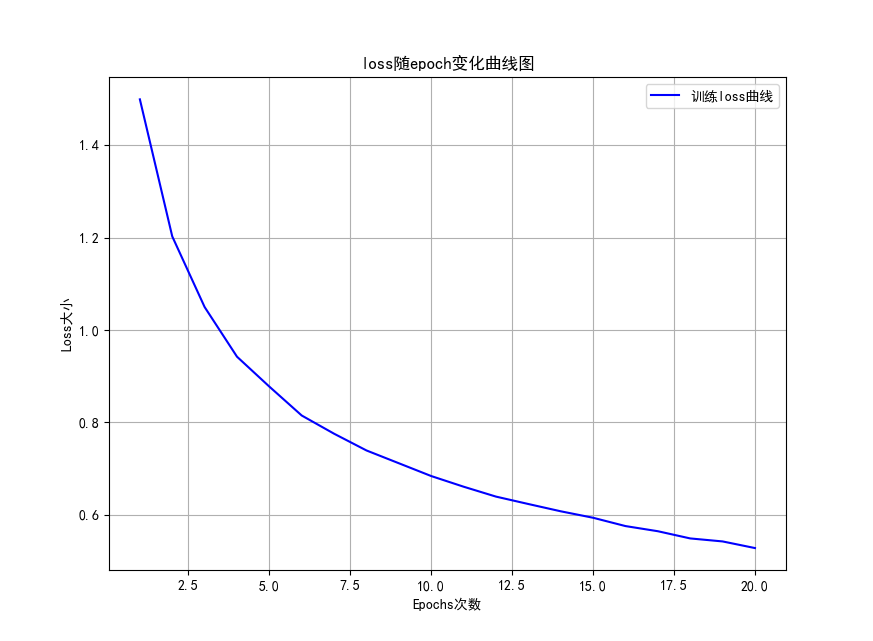
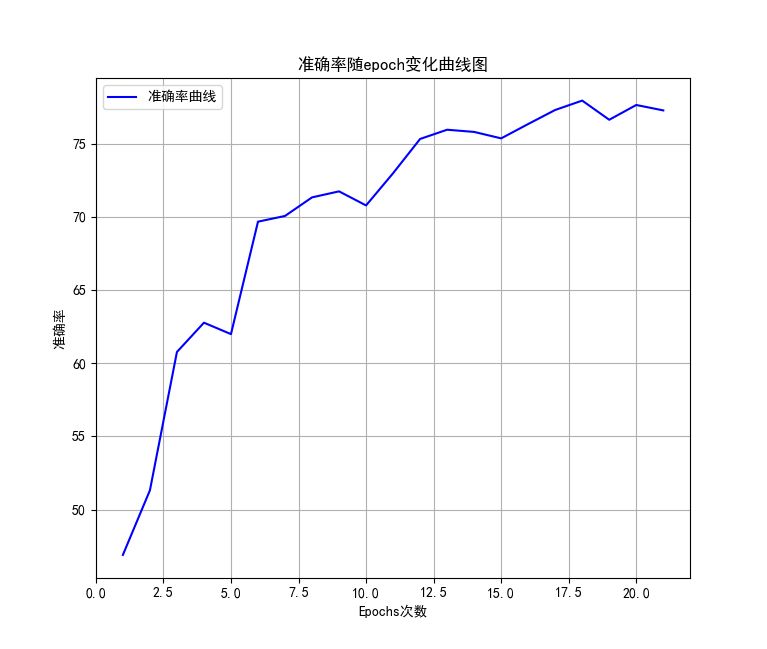
可以看到,即使只有一个残差层,收敛速度也是很不错的,准确率也能飙到四分之三以上。
可惜的是,电脑性能不充足让我没办法做一个标准的ResNET18,效果应该会更佳。